The governance flywheel: when recurring review findings write their own methodology rule
Every AI review finding already lands in a per-case worklist. But the patterns across cases were going unread. The flywheel reads them — and when a weakness has truly recurred, it proposes one grounded SKILL.md rule into the queue you already approve from. The SQL decides. The model only phrases. A human still signs.
A worklist nobody was reading sideways
Our AI review pass flags weaknesses one test case at a time: a missing negative path here, an untestable assertion there. Each finding lands in a persistent, resolvable worklist on the case it belongs to. That part shipped, and it works. But a worklist is read down — case by case, reviewer by reviewer. Nobody was reading it sideways.
Reading sideways is where the real signal lives. When the same category gets flagged on case after case across a whole suite — thirty-eight percent of imports have no negative path, say — that is no longer thirty-eight individual annotations. It is one sentence missing from your methodology. The per-case loop teaches one case. It never teaches the method, so the team keeps re-discovering the same gap by hand.
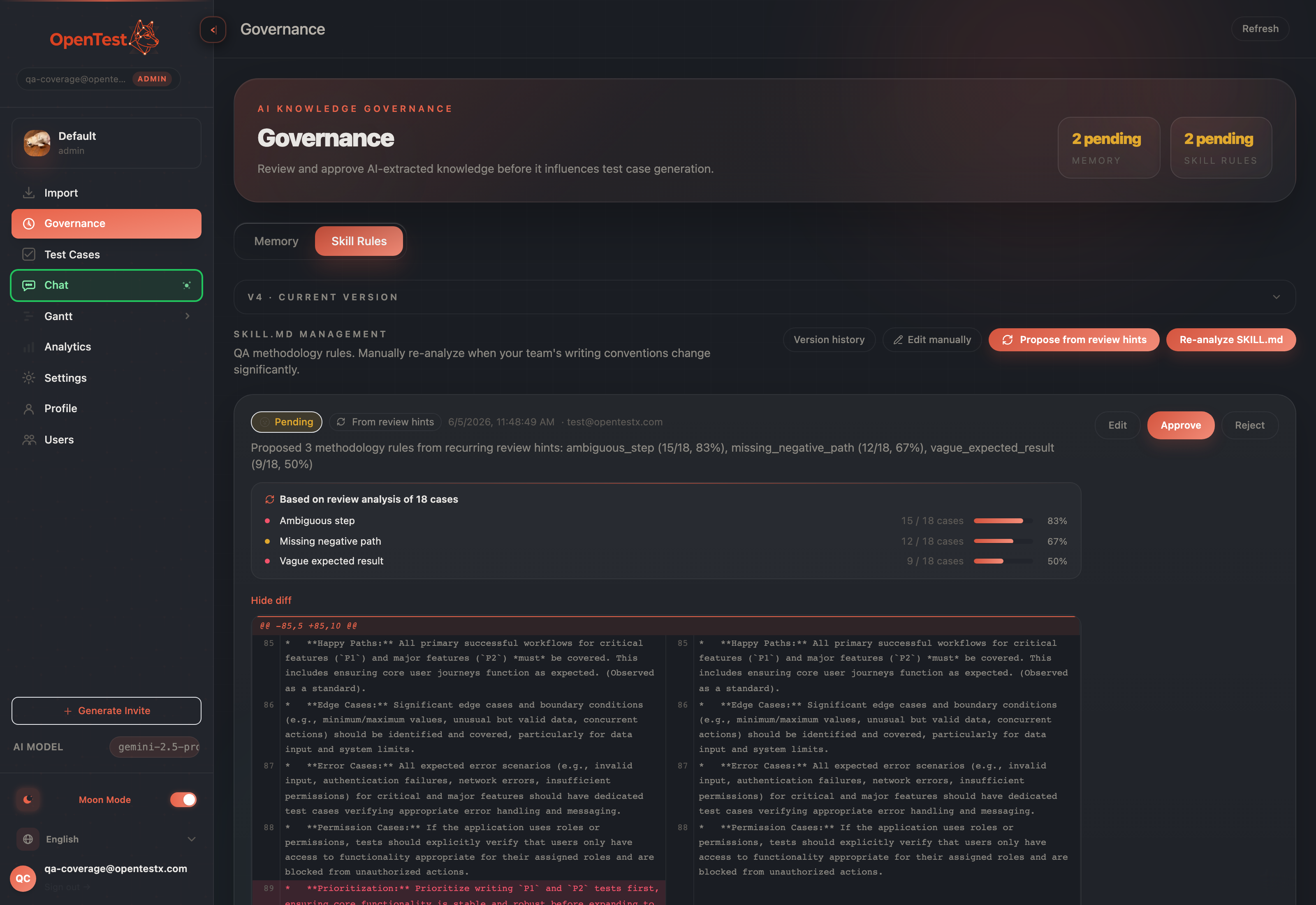
A real proposal card: the rule the model wrote, with the evidence that earned it — which categories, how many of how many analyzed cases.
The governance flywheel reads the worklist sideways — and when a weakness has truly recurred, it proposes the rule that would stop it at generation time.
The SQL decides. The model only phrases.
The order of operations is the whole design. A deterministic SQL aggregate runs first: group the findings by category, count the distinct cases each one touched, and divide by the analyzed population. Only a category that crosses a configured threshold — by default coverage ≥ 30% and at least eight cases — becomes a candidate. Below the line, the function returns nothing and the model is never called. The cost guard is structural, not an afterthought: no signal, no spend.
Only when arithmetic has already decided that a rule is warranted does the model get a job, and the job is narrow: write the prose for an already-justified rule. It never decides whether a rule should exist. That call belongs to a count of real, persisted findings — never to a model's opinion of what good QA looks like.
The denominator that fires hardest in the healthiest workspaces
The single correction that mattered most never touched a line of UI. It was the denominator. The naive ratio divides flagged cases by cases-that-got-flagged — which is almost always near one, so every coverage number reads enormous. We caught it before ship: a category flagged on eight cases reported as forty-two percent when the honest analyzed-rate was four percent.
So the denominator is the distinct cases that completed an analysis job — including the cases that were analyzed and came back clean, writing zero findings. That inclusion is the point. A clean case is evidence the method is working, and it belongs in the denominator. Drop it, and the naive ratio fires hardest in exactly the workspaces with the fewest problems — manufacturing rules a healthy suite never needed. Eight of two hundred is four percent, and four percent proposes nothing.
Provenance the approver can see, and the rule can't outrun
A reviewer asked to approve a machine-proposed methodology rule deserves to see why. So every flywheel proposal carries an immutable snapshot, written at the moment of the decision: which categories crossed, how many of how many analyzed cases, what coverage. The card renders it as the bars in the figure above — the evidence, not a black box.
It is a snapshot on purpose. Recomputing it at read time would let it drift away from the diff the reviewer is actually approving, the moment a finding is later resolved or dismissed. The number the approver sees is the number that earned the rule, frozen.
The proposal lands in the queue you already use — same approve, same reject, same versioning, zero new approval surface. Three guards keep it honest:
An approved rule never nags again. If the active SKILL.md already covers a crossed category, it is dropped before the model is ever called — no second proposal for a problem already solved.
Hint text is fenced as data. Finding text is reviewer-authored, so it is treated as untrusted input to the prompt; a deterministic backstop refuses any attempt to smuggle a URL exfiltration instruction through it.
The prose must scope itself. An adversarial eval blocks any blanket “every test case must…” rule from versioning. A rule about negative paths has to bound itself to state-changing operations — not impose itself on read-only cases it would never apply to.
The loop learns to not need itself
Here is the part worth the post. Once a human approves the rule, it versions into the live methodology and loads into the system prompt on every future generation. Newly generated cases stop carrying the weakness. The category's coverage falls back below the threshold. The flywheel proposes it no more.
Review findings literally become better generation, and then the signal that produced the rule decays on its own. Review hint → better case and better rule → better generation → fewer hints. A self-correcting loop that, working as designed, learns to stop needing itself.
What this is, and what it is not
Honest scope, because the trust is the feature. The flywheel writes only to SKILL.md — your testing methodology. It is contractually barred from touching MEMORY, your business context; the two are different kinds of knowledge and the analyzer never crosses the line. The thresholds are tunable defaults in a config file, not magic numbers — calibrate them to your own data. And nothing reaches your live methodology without a human approving it. The SQL earns the proposal. You still sign it.
Curious how this looks inside your team?
Book a short consult and we will walk through how OpenTestX maps to your current QA system.
Book a consultation →Related posts
How we kept a red-team feature from being security theater
The hardest part of shipping a red-team feature isn't writing attacks — it's not faking them. Our merge gate: every attack bank must make a vulnerable agent go red and a hardened agent go green, or it fails the build. A probe that can't tell a broken agent from a fixed one is theater. This is the gate, and the three real bugs it caught by going red first.
Red-teaming an agent, without writing a single attack: a walkthrough
We added promptfoo's red-team thinking to Eval Studio by fusing it into the eval spine instead of bolting it on — our leak-veto was already an attack grade. This post is the concrete walkthrough: pick attack plugins from a library, run them against your agent, and read a matrix that says 'held against this probe' — never 'safe'. Built and merged, not yet deployed.
An access-control eval that actually arrives as the user
An access-control test is worthless unless the request arrives as the role being tested. So in Eval Studio each role carries a real credential — a pasted revocable token, or one minted against your own endpoint — and a cross-role leak-veto runs as an engine default, not an opt-in. This post walks through setting one up. Built and merged, not yet deployed.