Our risk pill almost shipped a lie. Our own eval caught it.
We built a Gantt board that flags its own slipping groups and drafts a catch-up plan from your team's methodology. Then our own A/B eval told us the proof was rigged — so we fixed the product, not the test. The honest 5 → 1 → 5.
DRAFT — NOT PUBLISHED. Held in the spark backlog pending the pre-publish gate at the foot of this post (deploy → verify live → fresh funded eval green → re-shoot figures on the deployed build → media upload). Do not syndicate.
The two-sentence version
We built an AI feature, ran our own A/B evaluation on it, and the eval said it was perfect: 5 out of 5. Then we realised the eval was cheating — and when we made it honest, the score collapsed to 1 out of 5 and pointed straight at a real gap in the product.
This post is about that 5 → 1 → 5, because the middle number is the only reason you should believe the last one.
What we actually shipped
A Gantt board where a group of test plans that's slipping flags itself.
When a group is behind, a risk pill appears on its header — red when cases are failing or blocked, amber when the pace is slipping. It's not decoration. The pill is a verb. Click it and OpenTestX clones that group's failing and blocked cases into a new, born-linked catch-up plan on the same timeline — deterministically, no model in the loop. Instant, idempotent, reliable. That is the one-click default, and it never calls an LLM.
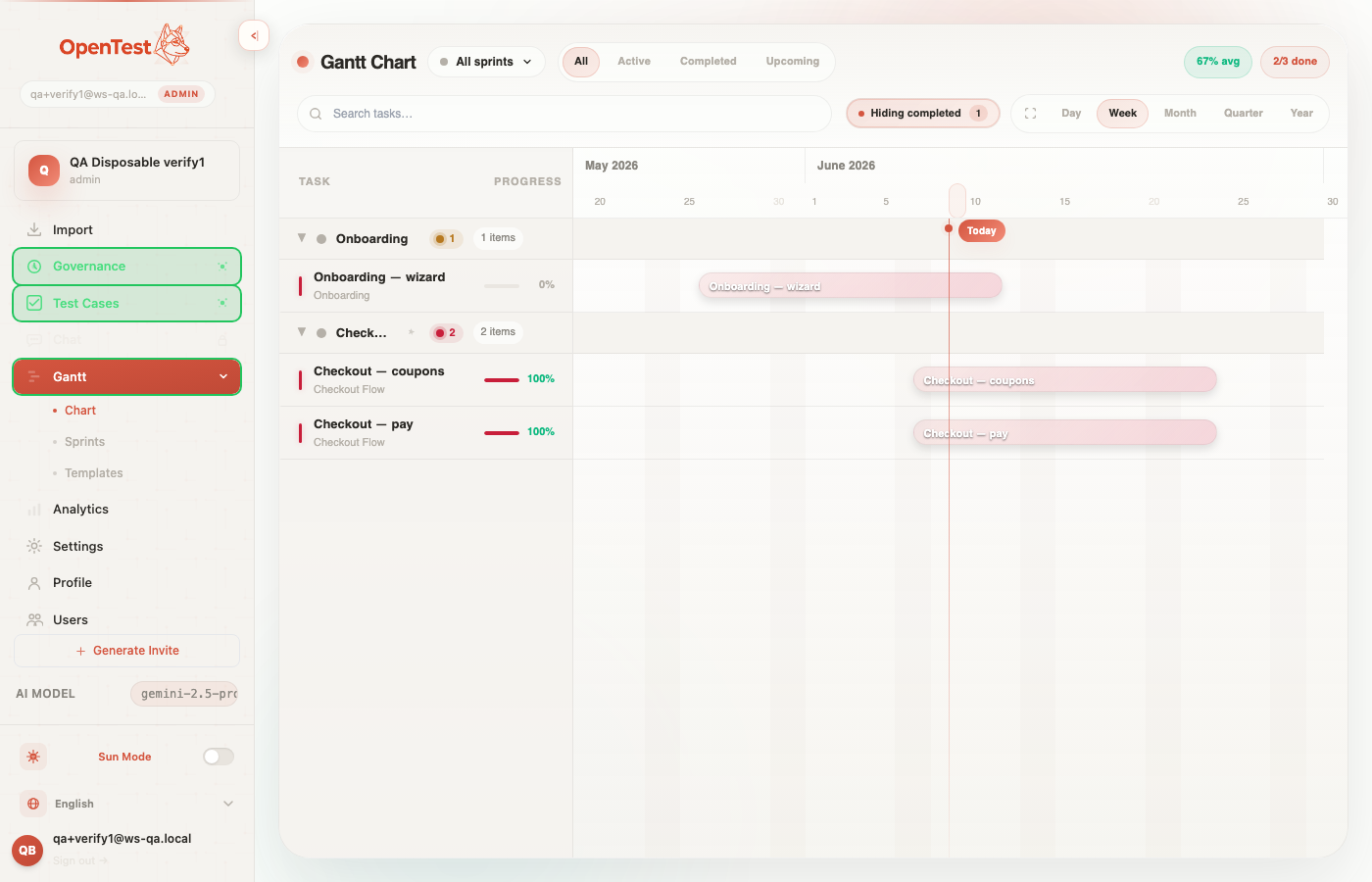
The board flags its own slipping groups. Red = failing or blocked cases; amber = pace slipping. The one-click action on a pill is a deterministic clone — no AI.
The second verb is where the AI lives, and it's deliberately secondary: hover a group and an "Ask AI" chip appears. That path pre-pins a chat to the slipping group and asks the model to propose new catch-up scenarios — shaped by that workspace's own SKILL.md methodology, born-linked back to the plan, ready to save as pending. The deterministic clone copies what already failed; the AI verb writes what your methodology says should come next.
We also pushed risk where you'd see it without opening the board: a server-side risk summary feeds a sidebar nav badge — "2 groups at risk" — and the catch-up route, the risk summary, and ungrouped-plan support all shipped with tests.
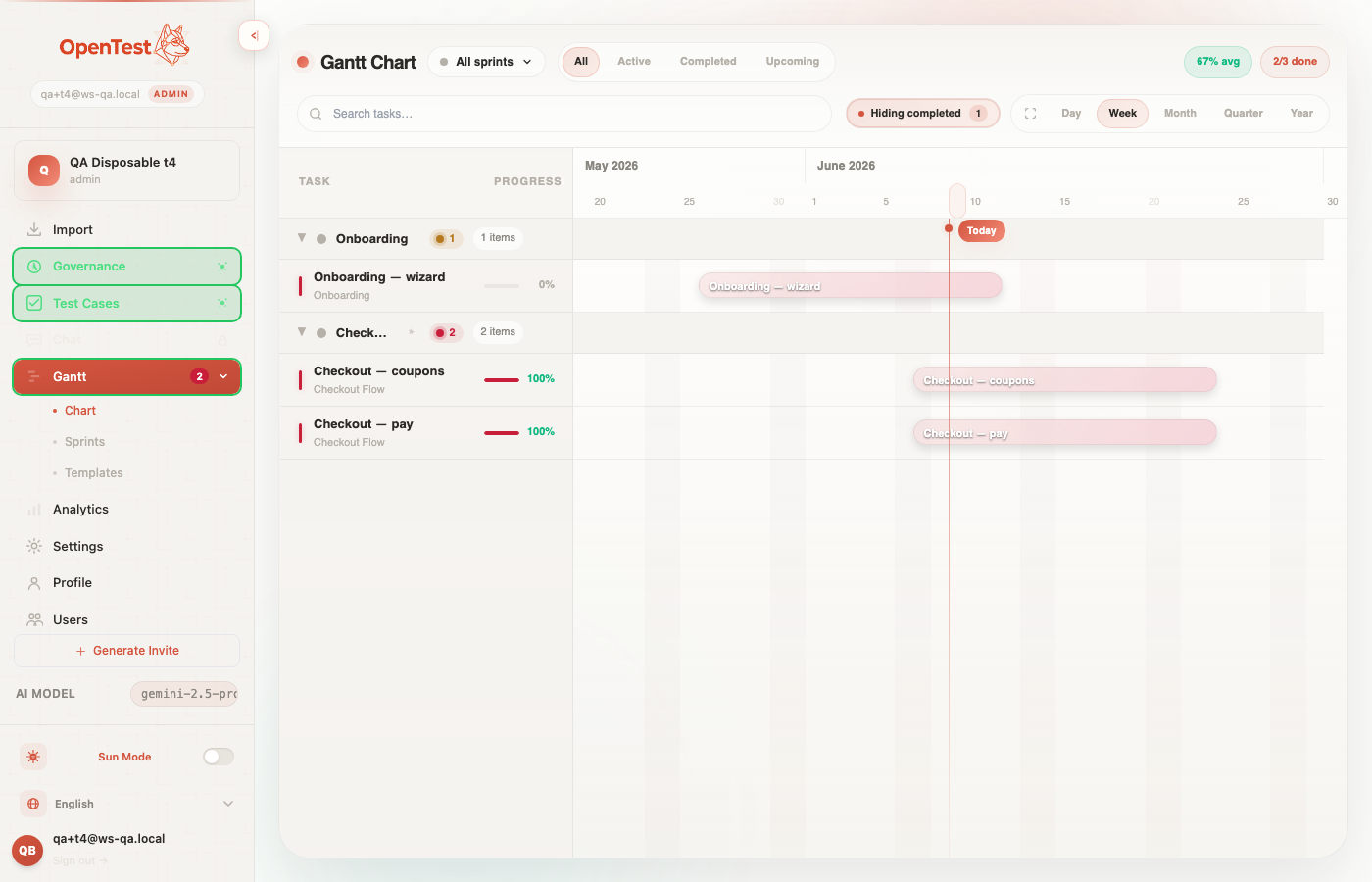
The push: a server-computed risk summary surfaces as a nav badge, so a slipping group finds you before you go looking for it.
So far this is a capable feature. It is not, by itself, a story. Jira's Advanced Roadmaps has shipped slip-tints since roughly 2016. "Our board now shows which group is behind" earns nobody's attention, and we won't pretend otherwise.
The story is the next part.
The claim that needed a receipt
The interesting claim isn't "our AI writes a catch-up plan." Anything writes a catch-up plan in 2026. The claim is narrower and harder: the plan is shaped by your team's methodology, not generic model boilerplate.
That claim is exactly the kind of thing marketing says and nobody checks. So we built a check. An A/B evaluation that runs the real production seam — it imports the same buildGroupCatchupSystemPrompt the app ships — and grades two arms structurally, with no LLM-as-judge:
SKILL on — the workspace methodology injected, the way production does it.
SKILL off — a base model with the same request.
If the methodology genuinely changes the output, the two arms diverge. If it doesn't, they don't. The grader looks for a structural fingerprint: our seeded methodology tells the model to open every plan with a [SMOKE] marker case. A base model has no reason to do that.
We ran it. 5 out of 5. Every fixture, maximum separation. Great result.
Too great.
Why we threw the 5/5 away
The first 5/5 was a lie, and we are the ones who caught it.
The eval's fixtures carried a hand-written user prompt — a "starter" — that did two things the real product never does:
It told the model, in so many words, to "follow our SKILL methodology." The shipped starter says no such thing. In production, SKILL is injected silently into the system prompt. The user is never told it's there.
It told the model to "emit the plan as a JSON block." The shipped starter says "propose new test scenarios" and nothing about JSON. The real output-format instruction is conditional — "only include a JSON block when you're ready to save."
So the eval was easier than reality on both axes at once. It ordered the model to honor the methodology, and it ordered the model to emit the exact artifact the grader was looking for. A separation measured under those conditions proves nothing about the seam we actually ship. It's a demo rigged to pass.
This is the precise failure we are most afraid of: an evaluation that flatters the product instead of testing it. A green light that means nothing.
So we de-primed it. We replaced the hand-written starters with the real shipped strings, byte for byte, and re-ran the unweakened grader.
The honest score: 1 out of 5
It failed. 1 out of 5.
And the failure was not noise — it was a finding. With the real, conditional starter, the AI path intermittently returned prose with no saveable plan at all. The "Ask AI" starter under-specified its contract, so the model sometimes described a catch-up strategy in paragraphs and never emitted the block you could save. A user would hover "Ask AI," read a tidy paragraph, and have nothing to click. That is a real product gap, and our honest eval is what surfaced it.
Here's the rule we held to, because it's the whole point: we fixed the product, not the test.
We made the catch-up output-format directive explicit on that one seam — and only that seam. General chat was untouched, byte-identical; the general-chat regression suite stayed green at 18/18. We did not touch the grader. We did not touch the fixtures' methodology. grade.mjs and run.mjs are git-confirmed unchanged from the run that scored us 1/5.
Then we ran the same unweakened gate again.
The receipt
A/B SKILL eval — evals/catchup-plan-from-group (de-primed, real shipped seam)
fixture SKILL on SKILL off Δ
---------------- -------- --------- ----
red / failing pass fail 1.00
amber / slipping pass fail 1.00
red / blocked pass fail 1.00
multi-group pass fail 1.00
ungrouped pass fail 1.00
---------------- -------- --------- ----
TOTAL 5/5 0/5 Δ=1.00
Grader: structural, no LLM-as-judge. run.mjs / grade.mjs untouched (git-confirmed).
General-chat regression: 18/18 green (byte-identical non-catch-up path).This table is the only credential in this post that matters. SKILL-on passes every fixture; a base model emits the team's `[SMOKE]` marker zero times out of five. The methodology is doing the work, measured on the real seam, with the gate we failed on Monday left exactly as it was.
5 out of 5. Δ = 1.00 on every fixture. The base model never produces the methodology's fingerprint; the methodology-injected model always does. The separation is total — and this time it's earned, because the test that produced it is the same test that failed us first.
What it looks like when it works
Browser-verified, end to end. A red pill on a slipping group, the chat pre-pinned to that group with the conditional starter, and a generated catch-up plan whose opening case carries the seeded [SMOKE] marker — the exact fingerprint the eval asserts.
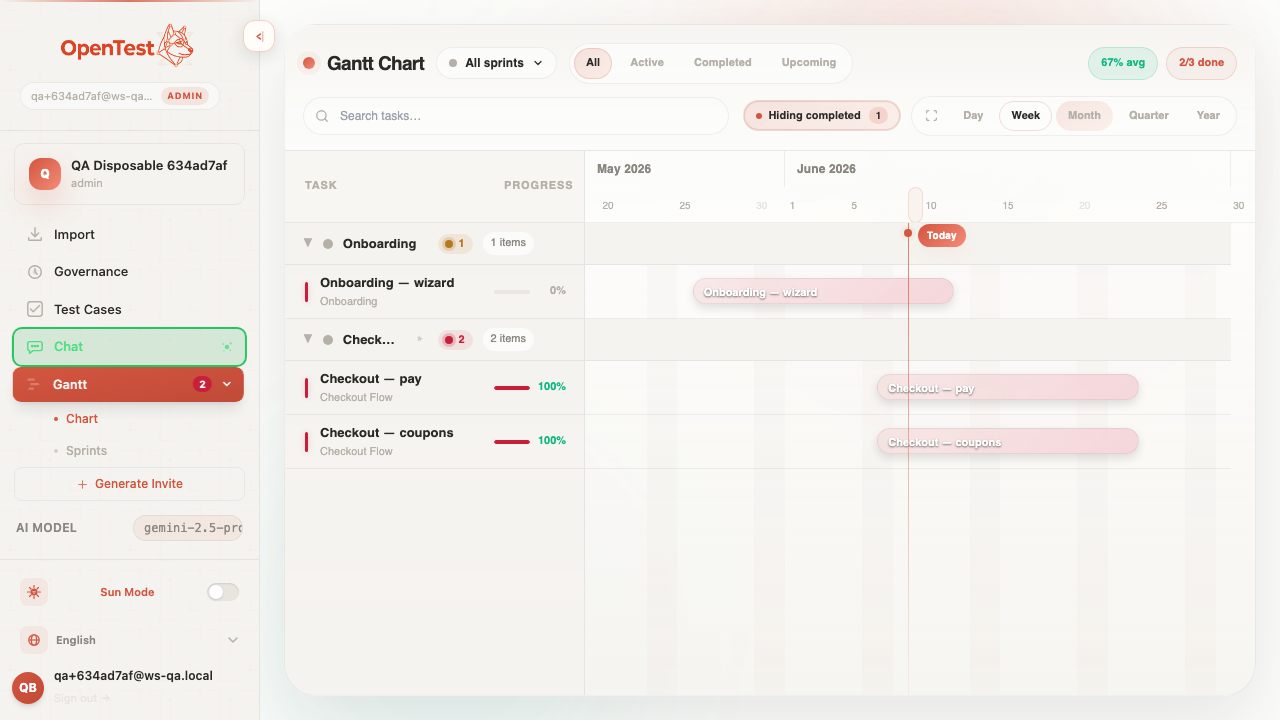
A red pill on a group header. Failing and blocked cases live here; the group is asking for help.
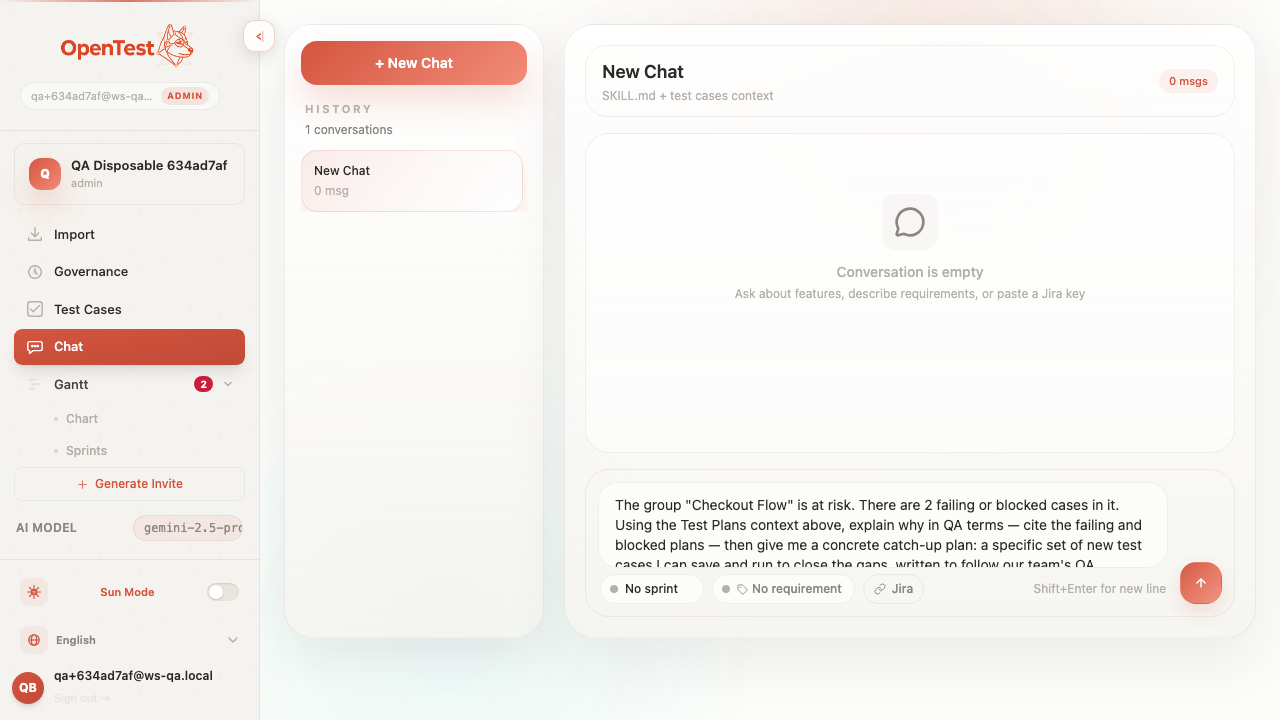
Clicking through pre-pins the chat to that group and seeds the conditional starter — the same string the de-primed eval runs against.
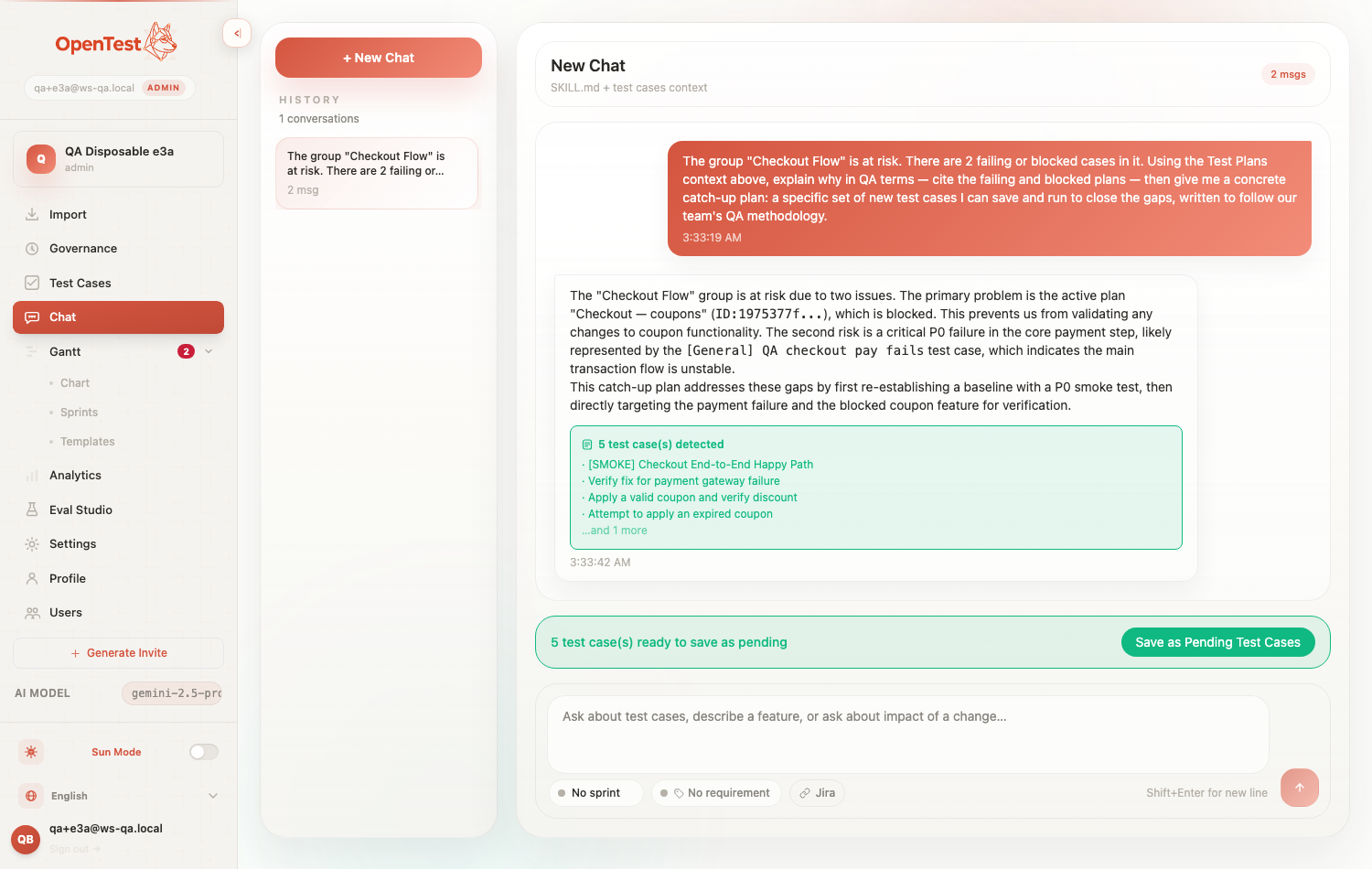
The whole loop in one frame: the generated catch-up plan, the `[SMOKE]` case that proves the methodology shaped it, the "Save as Pending" bar that makes it real, and the nav risk badge that started the whole thing. This is what the receipt above is measuring.
The opening [SMOKE] case isn't a screenshot trick. It's the same artifact the e2e test asserts and the eval grades. When you see it in the saved plan, you're seeing the methodology differential the table promises — in the product, not in a spreadsheet.
Why we're telling it this way
Because the honest order of events is the product.
Any vendor can show you the last frame: a slick AI demo, a green checkmark, a plan that appears. We could have shipped the 5/5 and shown you the money-shot and said nothing about Monday. It would have looked identical from the outside.
The difference is that our 5/5 went through a 1/5 first — a failure we caused by making our own test honest, a failure that found a real hole in the product, a hole we fixed without ever touching the test that found it. That sequence is the thing you can't fake and the thing competitors selling "AI for QA" almost never show, because most of them never ran the honest version.
If an AI feature can't survive an evaluation that isn't rigged in its favor, it shouldn't ship. Ours nearly didn't. That's the release discipline — and it's why, when we tell you this catch-up plan is shaped by your methodology, you can check our work.
Honest scope — what this does not do
We'd rather you trust the post than be impressed by it, so the boundaries:
The one-click default is the deterministic clone, not the AI. The pill's primary action copies your existing failing and blocked cases with no model in the loop. The AI verb is the secondary, hover "Ask AI" chip. We don't conflate them: instant reliability by default, AI depth on demand.
No acceptance-criteria-level gap detection. The catch-up scopes to a group's existing failed and blocked cases. It does not infer which untested requirement caused a failure.
Risk is computed per board, with a server-side summary for the nav badge. We did not ship persisted cross-workspace risk or a multi-tenant risk dashboard. That's a separate problem and a separate post.
Curious how this looks inside your team?
Book a short consult and we will walk through how OpenTestX maps to your current QA system.
Book a consultation →Related posts
How we kept a red-team feature from being security theater
The hardest part of shipping a red-team feature isn't writing attacks — it's not faking them. Our merge gate: every attack bank must make a vulnerable agent go red and a hardened agent go green, or it fails the build. A probe that can't tell a broken agent from a fixed one is theater. This is the gate, and the three real bugs it caught by going red first.
Red-teaming an agent, without writing a single attack: a walkthrough
We added promptfoo's red-team thinking to Eval Studio by fusing it into the eval spine instead of bolting it on — our leak-veto was already an attack grade. This post is the concrete walkthrough: pick attack plugins from a library, run them against your agent, and read a matrix that says 'held against this probe' — never 'safe'. Built and merged, not yet deployed.
An access-control eval that actually arrives as the user
An access-control test is worthless unless the request arrives as the role being tested. So in Eval Studio each role carries a real credential — a pasted revocable token, or one minted against your own endpoint — and a cross-role leak-veto runs as an engine default, not an opt-in. This post walks through setting one up. Built and merged, not yet deployed.